
Demystifying LLMs: Building Intuition for Conversational AI and Its Underlying Mechanics
Learning about how Transformers work should not require a PhD - going below the surface to examine how transformers work
Introduction
LLMs are now the tool du jour. Everyone is using ChatGPT, and it feels like every other blog post and article attempts to explain how ChatGPT and similar systems work. I am sure you have all seen the figure below, Figure 1 from “Attention is All You Need” paper from 2017. How many of you feel like you understand all - or any - of the terminology and key concepts which underly most modern LLMs?

When trying to design products and make business decisions related to the use of AI/ML technology, especially for conversational and generative AI, understanding that tech is a prerequisite. This post is intended to develop an intuition of what is possible, how things roughly work.
When talking about conversational AI or more specifically Large Language Model-based systems such as ChatGPT, Dolly 2, GPT4All, StableLM, h2oGPT, HuggingChat, … they are all very similar in the basic structure of how they work. Details will be provided below, but at the highest level:
Tokenization: Input text is broken down into smaller units called tokens. These tokens can be words, subwords, or characters, depending on the model's design.
Embedding: Each token is converted into a fixed-length array of numbers, called an embedding. These embeddings represent the token's meaning in a continuous space, and are commonly learned via “self-supervised training” - basically feeding the system hundreds of Millions of documents.
Position encoding: To capture the position of each token in the sequence, a position encoding is added to the embeddings. This helps the model understand the order of the words in the input.
Attention and Transformer calculations: The position encoded embeddings pass through multiple layers of the Transformer architecture. Each layer consists of two primary operations: self-attention and feed-forward neural networks. The self-attention mechanism allows the model to weigh the importance of each token in relation to others in the sequence, while the feed-forward networks help learn non-linear relationships between the tokens.
Output probabilities: After going through the Transformer layers, the model generates a probability distribution over all possible tokens in the vocabulary for each position in the sequence. This represents the likelihood of each token being the next word in the output.
Token selection: The token with the highest probability is selected as the output for that position.
Repeat: Adding the selected token to the end of, and continue from 2, until a predefined stopping condition is met, such as reaching a maximum length or encountering a special end-of-sequence token.
Tokens and Encoding
The initial input (prompt) to any of these types of systems is some block of text, a sequence of characters. In order to process the text, the system maps that text to tokens. Tokens can be characters, sub-words, or whole words. GPT-3 has 50,257 unique token ids, which can represent almost anything that can be written ranging from regular English: “Abraham Lincoln” —> [4826, 13220, 12406] to Chinese 阳光 —> [165, 246, 111, 46268], even emoji 👋🌍 —> [41840, 233, 8582, 234, 235].
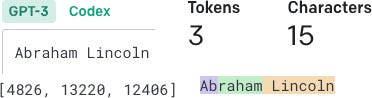

Since there are less than 65,536 (2 Bytes) and they are determined as a result of analyzing input text, the representation is highly efficient and makes performing matrix operations easier to compute.
ChatGPT-3.5 or ChatGPT-4 can “understand” a wide variety of input and produce a wide variety of output “languages”.


Encoding is the the first stage of processing by ChatGPT, where textual input is converted to a token array. Every different base LLM has its own encoding/token-map. For example, in BERT, there are special symbols [CLS], or beginning of a sentence and [SEP] end of sentence. Also, not always shown, it is common practice to pad unused tokens with a value of 0.

Tokens to text is always 1 to 1, but in theory there could be more than one set of token ids that map to the same output. For example in GPT-3 [18, 13, 23756] maps to “3”, ”.”, ”141” or “3.141” but so does [18,13,1415,16] which is: “3”, “.”, “14”, “1”.
Embeddings
When you read a word say: “dog” or “puppy”, in your head you view them as concepts. Embeddings are a way to map from token-space into '“concept space”. The basic idea is that you can have a dense vector that captures the “meaning” of any “thing” in the world.
To help explain embeddings, imagine Jane is a person trying to decide what movie to stream out of four possible movies: Frozen (2013), Cool Runnings (1993), Zodiac (2007), and The Conjuring (2013). Using embeddings, we can represent each movie as well as Jane’s movie preferences, and using that we can predict which movie(s) she is likely to be most interested in. For this example, we view the world in two dimensions, “fact vs fiction” (truthiness) and “Scary vs Family friendly” (scariness). If we imagine every movie has a score from -1 to +1 on each dimension, we might map the movies as follows, shown on graph:
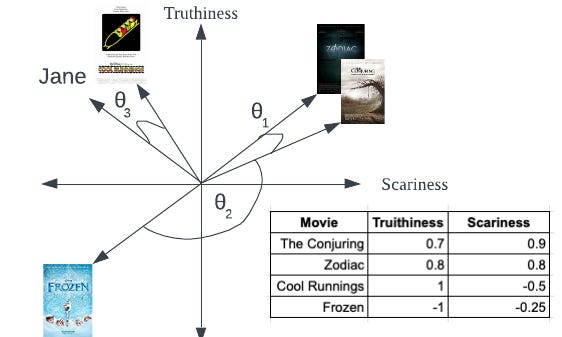
In this case, The Conjuring, which is 0.9 scariness and 0.7 truthiness is very similar to Zodiac which is also mostly truthy and very scary. A movie like Frozen, which is the opposite end of those two dimensions is extremely different. We can also map Jane into this embed space, since she Jane generally likes documentaries (truthy) and prefers less scary, she can be put on this graph too. The embedding space is two dimensions and each movie or person has some value between -1 and +1 for each dimension.
A common technique in math and machine learning to compare two vectors is to calculate Cosine Similarity, or basically the angle between them. In general the smaller the angle the higher the similarity Cos(0) = 1, and cos(-180 deg) = -1 - basically comparing Frozen to the Conjuring (theta 2), which is about as opposite as you can get. Jane’s preferences (weights for each dimension) are very similar to Cool Runnings, and hence theta 2 is very small indicating a high level of similarity.
While this example is relatively simple and possible for a human to visualize (2-dimensions), LLMs have many more dimensions, and it is unlikely they are going to map to simple human understandable concepts. Specifically, GPT-3 uses 12,288 dimensions for its embeddings (for each token).
If anyone would like to see actual embedding code using either HuggingFace or OpenAI Embeddings, post in the comments. This post is already too long.
Embedding references:
Getting Started With Embeddings (HuggingFace)
Embeddings - Crash Course Video (Google Developers)
Neural Network Embeddings Explained (older but relevant)
How do LLMs determine embeddings?
How most large LLMs (based on the encoder-transformer-decoder architecture) work today is to start with a pre-training or self-supervised learning. The ability for GPT-3, GPT-4, and similar models to be pre-trained without any supervision is one of the reasons why they can grow so large, and contain so much knowledge. In fact the “P” in GPT-3 stands for “Pre-trained”.
This paper will not discuss details of pre-training or self-supervised learning, the basic thing you need to know is the system takes a very large set of text (45 TB in the case of GPT-3) and produces an initial deep neural net that can be used to generate embeddings. Here are a few starting points to learn about a few different methods for pre-training:
You can think of the initial embeddings as a static mapping of each token to an embed vector (12,288 dimensions in the case of GPT-3). The problem is that having one embed vector per prompt token - which is up to 4K for GPT-3 and 32K for GPT-4 is a lot of data and by itself practical from a learning perspective.
To map that very large space (12,888 * 4000) or 51M values down to something more reasonable is necessary. This process varies slightly between different systems, but generally speaking it involves a few things:
positional encoding
attention
summation/reduction (referred to as Add & Norm) as shown in the first figure.
Positional encoding
Positional encoding is a way of encoding each token’s position that will not be lost when the 4000 embed vectors are combined. Although many readers might be familiar with “Bag Of Words”, which is where the inputs are thrown together in one big bag, without regard for relative position. This was very popular since it is both easy to implement and the math and processing is much simpler than dealing with combinations of words. Unfortunately, word order matters - a lot - especially for tasks like translation, and prompting in general. Think of any multi-word band name, or the classic: “dog bites man” (boring) vs “man bites dog” (scandalous).
The method used by GPT-3 for positional encoding involves adding small positionally based constants to each token’s corresponding embed vector based on a sinusoidal function. There are different methods for different underlying architectures. The details and reasoning are beyond the scope of this blog, but if you are interested here are a few easier to follow references: The GPT-3 Architecture, on a Napkin, Transformer Positional Embeddings and Encodings, Slide Talk: Demystifying GPT-3
Attention (is all you need)
The concept of attention is fundamental to the basic encoder-transformer-decoder architecture and was originally created to improve automated translation. This breakthrough significantly accelerated NLU (Natural Language Understanding) and NLP (Natural Language Processing) by allowing output token selection to be able to “focus” on what mattered, regardless of how far away in the token stream the currently important tokens are.
To understand attention in the context of a translation task, we can look at a case where a specific output word depends on multiple input words. As a simple example here are two sets of two English sentences: "I love my little dog. She's always by my side." and "I love my little dog. He's always by my side." In Spanish, and many other languages, certain words are masculine or feminine and the context is required to determine which word to use. In this case, when trying to translate the word “dog”, you need to “pay attention to” other words - in this case three English words: “little”, “dog” and “[s]he’s”. This specific case is even more complicated since the word she is actually in the following sentence. The attention mechanism can be summarized as for a given [output] token (i.e. the next one we wish to generate), what other tokens are relevant, and by how much.

By leveraging attention, it becomes possible when generating the next output token to reduce the entire input prompt and output so-far into a much smaller embedding that can contain all the relevant information, as opposed to explicitly “looking at” every other token. If you are using the HuggingFace library, it is very easy to see the raw attention values for a given task.
To see this in action:
import torch
from transformers import AutoTokenizer, AutoModel
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
def display_pooled_attention(input_text, model_name):
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# Tokenize input text and convert to tensor
inputs = tokenizer(input_text, return_tensors="pt")
# Get the attention from the model's outputs
with torch.no_grad():
outputs = model(**inputs, output_attentions=True)
# Get the attention weights
attentions = outputs[-1]
# Stack attentions and take the mean across all heads and layers
stacked_attentions = torch.stack(attentions).squeeze(1)
mean_attentions = stacked_attentions.mean(dim=(0, 1))
# Get token labels
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
# Plot pooled attention
plt.figure(figsize=(16, 8))
# we want to delete the first and last elements ([SEP], [CLS]):
reduced_attentions=np.delete(np.delete(mean_attentions,[0,15],1),[0,15],0)
sns.heatmap(reduced_attentions, xticklabels=tokens[1:-1], yticklabels=tokens[1:-1], cmap="viridis")
plt.xlabel("Tokens")
plt.ylabel("Tokens")
plt.title(f"Pooled Attention for '{model_name}'")
plt.show()
return mean_attentions
# Example usage
model_name = "bert-base-uncased"
input_text = "I love my little dog. She's always by my side."
mean_attentions = display_pooled_attention(input_text, model_name)
Although a little confusing, you can see in this English only data, “dog” is highly related to: “dog”, “she” (and the apostrophe s) and “little”. Likewise, the “I” has minimal attention for “little”, “by”, and “side” - all of which refer to the dog….
Multi-head attention
In order to develop deeper understanding and produce much more complicated outputs, many systems such as GPT-3 utilize more than one attention network. Specifically, GPT-3 has 96 attention blocks, each containing 96 attention heads. The large number of attention heads are estimated to consume about 30% of the 175 Billion parameters.
This paper will not go into too much detail about the lower-level implementations and deep-network structures associated with multi-head attention. Simply understand that multi-head attention is what can allow the system to focus on multiple different things simultaneously.
From GPT-4 summarized: “Multi-head attention allows the model to learn different types of relationships or patterns among the input tokens by computing multiple attention matrices in parallel. Each "head" in the multi-head attention mechanism can capture different types of dependencies or attend to different parts of the input, which can ultimately help the model to better understand the input and produce more accurate predictions or representations.”
Output probabilities, Selecting a token and repeat
The result of all of this very large multi-layer network is a set of probabilities. Each of the 50K possible tokens has a “score” and the system can select the highest one.
Technically not true probabilities, even though they will sum to 1, these final “scores” for each “class” (possible token) are used to select the next token in the sequence.
This blog will not go into detail on how multi-layer neural networks and softmax works, but we will dig in and using the OpenAI API actually examine the probabilities for a given output token.
It is important to note that these systems are autoregressive, in that after each iteration one token is selected and then fed-back to calculate the next token. The fact that the UI for ChatGPT actually renders like someone typing is actually due to the fact that it is calculating as it goes along.
Looking at the output probabilities….
Fortunately, the OpenAI API for completions allows you to return the probabilities and even multiple possible outputs. Unfortunately, the Chat API does not. However - using HuggingFace and other libraries, it is possible to view any part of the neural network at any step, although this blog will only look at one instance.
import os
import openai
from dotenv import load_dotenv
import numpy as np
load_dotenv()
ENV_DATA = os.environ
def query_openai(prompt, temperature=0.5, max_tokens=3, best_of=5, n=5, logprobs=5):
openai.api_key = ENV_DATA["OPENAI_API_KEY"]
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
max_tokens=max_tokens,
temperature=temperature,
best_of=best_of,
n=n,
logprobs=logprobs
)
return response
def analyze_response(response, token_position, show_only_probs=False):
# Logprobs --> probs === prob = e^log_prob
responses = [x['text'] for x in response['choices']]
tokens = [x['logprobs']['tokens'] for x in response['choices']]
# lets assume we only want the probs for the first choice (best) at token_position
probs = [(k,("%.5f" %(np.e**v))) for k,v in response['choices'][0]['logprobs']["top_logprobs"][token_position].items()]
if show_only_probs == False:
for i in range(0,len(responses)):
print("{} --> [{}], tokens: {}".format(i,responses[i].strip(),tokens[i]))
print("Probs for token \"{}\", index {}: {}".format(response['choices'][0]['logprobs']['tokens'][token_position],
token_position,probs))Lets take a prompt: “what are the first 5 digits of pi?” and examine the output (tokens) as well as what their probabilities were. What did it *almost* pick? Note that to ensure consistency, I set the temperature to 0. If you don’t you might get all kinds of varied outputs. This type of problem is not one where we want the system to “be creative”.
response = query_openai("what are the first 5 digits of pi?", temperature=0,max_tokens=20,n=1,best_of=1)
analyze_response(response,2)
analyze_response(response,3,show_only_probs=True)
analyze_response(response,4,show_only_probs=True)0 --> [3.1415], tokens: ['\n', '\n', '3', '.', '14', '15']
Probs for token "3", index 2: [('3', '0.99956'), ('The', '0.00033'), (' 3', '0.00007'), ('Answer', '0.00003'), ('2', '0.00000')]
Probs for token ".", index 3: [('.', '0.99994'), (',', '0.00005'), (' 14', '0.00000'), (' 1', '0.00000'), ('<|endoftext|>', '0.00000')]
Probs for token "14", index 4: [('14', '0.61023'), ('141', '0.38814'), ('142', '0.00095'), (' 14', '0.00065'), (' 141', '0.00003')]There are a few interesting points to note here (I actually have like 20 more points that are just too many for this post, but if you want to learn more ask in the comments or message me).
The output as rendered: “\n\n3.14159” - it inserted two newlines. Different prompts can add all kinds of different “fluff” i.e. “I would like to know the first 5 digits of pi” actually start the text with “The first 5 digits …”, and the prompt "first 5 digits of pi:\n" only starts with one newline
The first digit “3” has an extremely high probability of being selected, but it is interesting to see the system was considering starting with “The” or “Answer” or even “2” - possibly due to some people refer to pi as “22/7” (but really we may never know why given the extreme complexity of the model)
The decimal point while clearly the strongest also had a chance of selecting a comma (",”). In fact if you change the prompt to: "In French: the first 5 digits of pi?" it puts a comma instead of a period.
The 5th token (index 4) in this case was actually a close call between “14” and “141”, with a chance of selecting those with a space in front or even “142”.
As stated above, tokens to text is 1:1, but not the other way around. Even though the token sequence (and possibly the number of tokens) could vary, the rendered output might be the same.
The chance of picking “14” was about 60% while “141” almost 40%. I suspect the tokens “ 14” and “ 141” are due to either improperly extracted web content, or even cases on the web where a space appears before, I have seen this.
The problem with selecting one token at a time
Although it makes sense to pick one token, feedback (autoregressive) and then pick the next, sometimes this could get the system in trouble - especially if there is temperature-induced randomness. For example, imagine if the system somehow picked “2” instead of “3”, then the following tokens might be all screwed up. However, a sequence of tokens: “3”, “.”, “14” would be very strong as a set, even if for some odd reason the “3” was not the strongest.
One way to deal with this is something called beam search. Beam search allows the system to in a sense “look ahead” so it is maximizing the quality of the sequence, as opposed to being greedy.
Something I have noticed, is if you use ChatGPT-4 sometimes it is typing, then it backtracks. I suspect this backtracking is actually the way the system realized that a previous choice several tokens earlier might not have been very good and it changes it; either beam search, or something similar in terms of functionality.
Summary
Large Language Models based on the encoder-transformer-decoder architecture are extremely large, complex and opaque. There are probably thousands of papers (academic and blogs) and YouTube videos about this. Hopefully, this blog post gives you a little more intuition and some code examples so you can explore yourself.
Two other refs to learn about these architectures:
Transformer’s Encoder-Decoder: Let’s Understand The Model Architecture
HuggingFace Course - covers much of what is in this paper via a series of short videos and associated notebooks
I have notebooks and example code to access, view and utilize embeddings as well as other stuff. Just pop a comment with whatever you might find useful and I will try to post it somewhere. Working on creating a new repo for my next post....