
The Verifiable Orchestrator: A New Agentic Pattern to Break the "LLM-as-Analyst" Trap
Moving from "Black Box" predictions to transparent, verifiable orchestration
The Verifiable Orchestrator: A New Agentic Pattern to Break the “LLM-as-Analyst” Trap
In my previous post, I detailed five fundamental flaws of the “Simple Agentic Approach”, asking an LLM to act as both the planner and the execution engine.
Risk 1: The “Helpfulness Paradox” (Hallucination) The tendency of LLMs to “fill in the blanks” or hallucinate data to satisfy a user’s request rather than admitting a lack of information.
Risk 2: Probabilistic Processing vs. Deterministic Logic The inherent danger of using a probabilistic token-prediction engine to perform precise mathematical calculations or logical operations.
Risk 3: Lack of Native Domain Concept Understanding The inability of a static model to account for dynamic, real-world concepts (e.g., changing ticker symbols, evolving corporate policies, or local database schemas).
Risk 4: Operational Cost and Latency Explosions The inefficiency of “data dumping” raw datasets into a prompt context window, leading to massive token costs and slow response times.
Risk 5: Lack of Trust and Verifiability (Operational Opacity) The difficulty for non-technical users to audit the “black box” of LLM-generated logic or synthesized code.
The industry solution has largely been “better prompting” or heuristic guardrails. I argue we need something different: a better architecture.
We need to shift the role of the LLM from an Arbiter of Truth to an Orchestrator of Deterministic Tools.
This post introduces a new design pattern: The Verifiable Orchestrator. It is built on a methodology I call TRACE (Tool-Routed Architecture for Controlled Execution), designed specifically to ensure high accuracy, strong product control, and user trust in high-stakes domains like finance.
1. The Goal: From Oracle to Orchestrator
To solve the five key problems, we must fundamentally shift the role of the LLM:
From: An arbiter of truth and exclusive generator of output.
To: An orchestrator that performs research and plans actions using current business knowledge, while delegating all execution and output generation to deterministic tools.
1.1 Related Patterns
To understand this new approach, we contrast it with two related agentic philosophies:
ReWOO (Reasoning Without Observation)
Concept: Leverages distributed, intelligently planned knowledge-gathering actions. It focuses on efficiency by planning steps upfront to reduce prompt size, and maximize density of relevant information.
Limitation: ReWOO functions more like an intelligent RAG system than a complex multi-step data processing framework. It lacks the iterative feedback loop required for deep analysis. (arXiv:2305.18323)
CodeAct (Code as Action)
Concept: Focuses on maximizing flexibility by having the LLM write arbitrary Python code to solve problems. This offloads computation from the LLM to a Python interpreter, and leverages the LLM’s vast Python training data to enable more capabilities than limited tools. In addition, if the generated code is bad, errors are generated and the LLM is skilled at addressing the errors.
Limitation: While it solves the calculation problem, it suffers from trust and interpretability issues (risk 5), and does not address local knowledge related concerns (risk 3). There is no reasonable way for non-technical users to determine if the code written by the LLM is a correct interpretation of their request. (arXiv:2402.01030)
2. The Approach: The TRACE Framework
We present a novel framework designed to address the five risks of the “LLM-as-Analyst” trap. The TRACE (Tool-Routed Architecture for Controlled Execution) architecture ensures that:
Computation is pushed out of the LLM into precisely controlled, deterministically executed tools.
Data results are deterministically generated, unmodifiable by the LLM, and presented as raw data output.
Local knowledge is prioritized via dedicated information gathering steps.
Trust is established via a non-LLM-based deterministic summary of the steps taken.
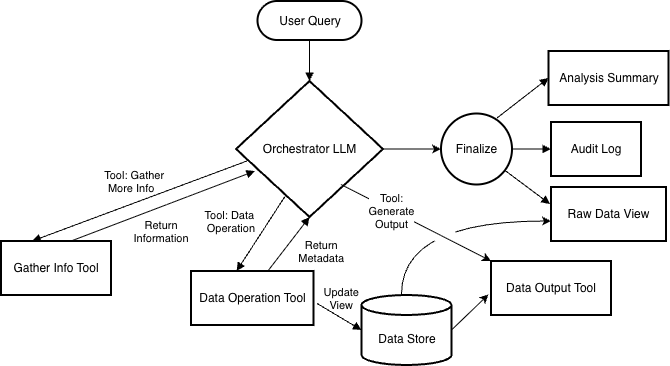
2.1 Workflow Logic: The Decision Loop
The core logic flow separates the Orchestrator (probabilistic reasoning) from the executor (deterministic data processing).
Receive Request: The Orchestrator receives the user prompt.
The TRACE Decision Loop: The Orchestrator iterates through three specific types of choices:
Choice 1: Gather Information (Read-Only). The LLM requests to “see” data samples or schema info, or call ‘research’ tools. This is non-destructive. The result is returned directly to the LLM to build context (Addressing Risk 3).
Choice 2: Execute Data Operation (Deterministic Transformation). The LLM selects a tool (e.g., filter, sort, join, window function, custom code). The tool executes deterministically, stores results in the immutable Data Store, and returns only metadata or errors (e.g., row counts, data summary) to the LLM (Addressing Risk 2 and Risk 4).
Choice 3: Execute an intermediate Output Tool. The LLM selects an output-generating tool (e.g., chart, save, email). This tool can read data from the data store to produce a deliverable i.e. a graph, csv-file, etc…
Choice 4: Finalize (Done computation): The data that best addresses the user’s query has been generated, and no more tools/actions are required.
Finalization: The system produces three distinct outputs:
Raw Data/Artifact: The final view (untouched by LLM) (Addressing Risks 1,2,5).
Audit Log: A deterministic, code-generated summary of the steps taken (Addressing Risk 5).
Analysis: An optional, and clearly indicated as “generated non-deterministically”, LLM-generated summary of the findings.
3. The Pattern in Practice: Illustrative Examples
To understand how TRACE (Tool-Routed Architecture for Controlled Execution) functions in the real world, let’s walk several examples of how a Verifiable Orchestrator handles complex requests compared to a standard “Black Box” agent.
Scenario A: The Multi-Step Analytical Query
User Request: “What is the 30-day moving average for the computer chip stocks? Pivot the results by ticker.”
The “Black Box” Failure Mode: Even if equipped with a standard database tool, an LLM might attempt to interpret “30 days” as calendar days rather than trading days, or try to pull tickers from its internal training memory rather than the live database. This often results in a correct-looking SQL query that returns factually incorrect financial data.
The “Verifiable Orchestrator” Workflow: The Orchestrator breaks this down into a transparent sequence of Research, Construction, and Finalization.
Research (Gathering Context)
Before touching data, the agent grounds itself in the current reality.
Time Resolution: It calls a tool to map “30 trading days” to specific dates.
Result: 2025-12-17 to 2026-01-30 (only days where the market was open).
Entity Resolution: It searches a groups metadata table for “computer” AND “chip”.
Result: Found group “CHIPS” containing current tickers: NVDA, AMD, INTC, AVGO, QCOM. (Crucially, this list is dynamic, not from the LLM’s static memory).
Function Discovery: It searches the equations library for “moving average”.
Result: Found SMA (Simple Moving Average): “A common measure to show mean movement over a specified window.”
Planning and Deterministic Execution
The agent now instructs the Deterministic Engine to build the dataset and process it accordingly.
Create New View: view_name=”chip_stocks_30”, source_view=”stock_data”, filter=”tickers=[NVDA, AMD, INTC, AVGO, QCOM], between [2025-12-17, 2026-01-30]”
System Feedback: “Loaded 180 rows. Columns: date (30 unique values), ticker (6 unique values), close (179 unique values).” (The LLM sees only this summary, not the raw numbers).
Apply Named Function: new_view_name=”chip_sma_30, source_view=”chip_stocks_30”, function_name=”SMA”, column=”close”, n=30
System Feedback: “Column ‘sma_30’ added. No errors, 174 rows contain NaN.”
Pivot Data: new_view=”pivot_sma_chip_30”, source_view=”chip_sma_30”, pivot_column=”ticker”, sort_column=”date”, ascending=False
System Feedback: “Pivot complete. 30 rows generated, 6 columns.”
Finalization
Finalize: final_view=”pivot_sma_chip_30”, sort=”date”, ascending=”false”, “limit=1”
The Result: The user receives a mathematically perfect table. The “Audit Log” shows exactly which tickers were used and how the date range was calculated.
Scenario B: Self-Correction (The “Hallucination” Check)
One of the greatest risks in agentic systems is confidence in outdated information or silent failures. Let’s see how the TRACE framework handles a change in the real world (e.g., Facebook changing its ticker to META).
User Request: “Show me the max trade volume for the FAANG stocks last year.”
The “Black Box” Failure Mode: An LLM relying on older training data assumes FAANG includes “FB”. If the database query for “FB” returns no results (rather than an error), the standard agent simply returns a table with 4 rows. The user sees a clean table and assumes it is complete, never knowing Facebook was omitted.
The “Verifiable Orchestrator” Workflow:
1. Initial Planning & Execution The Orchestrator relies on its internal (outdated) model and attempts to build the dataset.
Action:
create_view(name="faang_vol", tickers=["FB", "AAPL", "AMZN", "NFLX", "GOOGL"])
2. System Feedback (The Observation Loop) The deterministic tool runs and returns a Metadata Summary. This allows the Orchestrator to detect issues in two ways:
Method A (Explicit Error): The tool validates inputs and fails immediately:
Error: Symbol 'FB' not found.Method B (Metadata Mismatch): Even if the tool accepts the query, the returned summary flags the inconsistency:
“Success. View ‘faang_vol’ created. Rows: 1,000. Unique Tickers Found: 4 (AAPL, AMZN, NFLX, GOOGL).”
The Orchestrator compares the Intended State (5 tickers) vs. the Actual State (4 tickers) and recognizes a failure.
3. Research (Information Gathering) Instead of hallucinating a reason or giving up, the Orchestrator then triggers an information-gathering tool to resolve the specific discrepancy.
Action:
search(table=”company_data”, query="Facebook")Result:
Found: ticker=’META’, description=’Meta (formerly Facebook [ticker FB]) is a …’, company_name=’Meta’, symbol_effective_date=2022-06-09.
4. Iterative Correction Armed with the correct local knowledge, the Orchestrator updates the plan.
Action:
create_view(name="faang_vol_fixed", tickers=["META", "AAPL", "AMZN", "NFLX", "GOOGL"])Result:
Success. Rows: 1,250. Unique Tickers: 5.
5. Finalization
Action:
aggregate(view="faang_vol_fixed", func="max", col="volume", group_by="ticker")Result: A verified table with 5 rows. The Audit Log explicitly records the correction: “Initial query for FB failed; resolved to META.”
Scenario C: Complex Relative Logic
User Request: “For the car stocks, calculate the relative close price compared to the start of the period (30 trading days ago).”
This requires multi-step logic: getting a baseline value (Day 1) and dividing every subsequent day by that baseline. Below is a sample audit log that a user might see after getting the results.
The Audit Log (Generated by the System): The trust comes from the fact that the user can read the steps the system took:
Resolved ‘last_30_trading_days’ to 2025-12-17 – 2026-01-30.
Searched ‘groups’ for ‘car’, matched 6 rows: [‘category=’AUTOS’, ticker=’TSLA’, desc=”Autos covers car and truck companies”], [‘category=’AUTOS’, ticker=’F’, desc=”Autos covers car and truck companies”], … (see detailed logs for full result)
Created View ‘cars_30d’ from ‘stock_prices’ TICKERS=[”TSLA, F, GM, TM, HMC, STLA”], (7 columns, 180 rows, ), date range 2025-12-17 – 2026-01-30.
Aggregated ‘cars_30d’: on ticker, sorted by date ascending, to find the first value of close for each ticker. -> Created a new view first_close_per_ticker (2 columns, 6 rows).
Joined cars_30d with first_close_per_ticker, inner joined on ‘ticker’, created new view cars_joined, (8-columns, 180 rows, …)
Add_column: view=cars_joined, new_col=”relative_close = close / close_right”.
Finalized view cars_joined.
Because these steps are recorded by the Executor (the code), not the Orchestrator (the LLM), they serve as a perfect audit trail, and all tools execute deterministically so you can be certain the results are correct for the tool inputs presented.
4. Addressing the Business Risks
The combination of the above mechanics directly addresses the initial problem set:
The Helpfulness Paradox: The LLM doesn’t generate the raw data result; it only acts as an orchestrator. The final output includes a direct dump from the deterministic engine. If the LLM can’t find a valid path through the tools, there is no data output, rather than hallucinated results.
Probabilistic Processing vs. Deterministic Logic: All logical operations and calculations are handled by the Tool Executor, ensuring 100% mathematical accuracy (with regards to the tool’s probabilistically selected parameters).
Lack of Native Domain Concept Understanding: The “Gather Info” loop allows and encourages the LLM to gain local knowledge before acting via current state in the DB or special tools designed to map to domain-specific concepts. (e.g., “What is the current stock symbol for SOME COMPANY”, or “What would be the start date for ‘30 trading days ago’?”).
Operational Cost and Latency Explosions: The LLM only processes results of information gathering steps or tool-response metadata (less tokens than full data), not raw datasets. Large data operations happen outside the context window.
Lack of Trust and Verifiability: The “Audit Log” and raw data result are generated by the code that ran the tools, providing a verifiable truth of what actions were taken. This truth could be saved and replayed deterministically - without the LLM’s involvement.
5. Trade-offs and Implementation Considerations
While the Verifiable Orchestrator significantly mitigates the hallucinations and operational opacity of simple agents, it introduces new engineering requirements. The choice between these patterns depends on the balance between flexibility, cost, and the need for auditability.
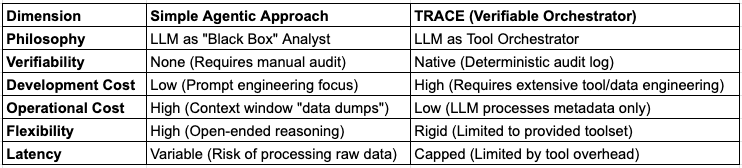
5.1 Development Velocity vs. Reliability
The “Simple Agent” is very fast to prototype, as it relies on the LLM’s inherent capabilities to process data, mitigating the need for complex tools or code. However, for high-stakes domains, such as finance or healthcare, where liability is attached to errors, the TRACE framework offers necessary guarantees. This reliability comes at the cost of upfront engineering; organizations must shift from prompt engineering to building a deterministic software layer that the LLM can control.
5.2 Engineering Prerequisites
Unlike general-purpose chatbots, a Verifiable Orchestrator’s functionality is bounded by the set of tools and data.
Tool Completeness: The system cannot answer questions if a specific tool or capability (e.g., “rename column”) has not been built.
Schema Clarity: The Orchestrator relies on clear API definitions and descriptions to select the correct tool and parameters. Ambiguity or lack of clarity in tool names or parameter definitions leads to planning errors.
Rich Error Handling: To enable self-correction (as seen in the “FB vs. META” example), tools must return structured metadata and descriptive errors, rather than failing silently.
5.3 Residual Probabilistic Risks
While this architecture removes non-determinism from calculations, it does not remove it from instructions. The Orchestrator remains a probabilistic model, two primary risks persist:
Tool Selection: The model may select a valid tool that does not match user intent (e.g., filtering instead of sorting).
Parameter determination: The model must correctly map natural language to tool parameters (system entities) (e.g., mapping “Facebook” to “META”) before deterministic tools can execute.
5.4 Performance and Latency
The Simple Agent often suffers from “context bloat,” where passing raw datasets to the LLM increases costs and latency. TRACE avoids this by keeping data outside the context window. However, this introduces a different latency profile: the overhead of multiple sequential tool calls (the “Decision Loop”). For trivial queries on small data, a Simple Agent may be faster, but for complex analysis on large datasets, the Verifiable Orchestrator is more scalable and cost-efficient.
6. What’s Next?
This post defined the Verifiable Orchestrator pattern as a blueprint for auditable, high-accuracy agents.
In my next post, I will share the libraries and tools required to implement the TRACE framework. We will walk through a fully functional financial agent, demonstrating the capabilities of this new pattern.
Conclusion
The “Simple Agent” approach asks the LLM to act as a computer, a task it is ill-suited for. The Verifiable Orchestrator shifts the LLM’s role to what it does best: reasoning and planning.
By separating probabilistic intent from deterministic execution, we can build systems that are trusted and verifiable. While this approach requires significant investment in tooling and architecture, it provides the control necessary for production-grade applications in critical industries.
AppliedIngenuity.ai is dedicated to making AI accessible to everyone. We focus on solving the real-world business problems that prevent companies from creating effective products. To learn how we can help your business, reach out to us at ai_consulting - at - appliedingenuity.ai.
great article. do you have code snippet to show how Deterministic Engine works?