
Case Study: Building a Trustworthy Agentic AI Chatbot for Medical Credential Management
How governed orchestration let Credential Network build an agentic AI chatbot to meet stringent compliance and internal security requirements
Part 2 of the AI Risk series
Credential Network and CredAssist
Provider credentialing is the work of verifying that a clinician is who they claim to be and holds the licenses and qualifications they claim to hold, then maintaining that record over time. It currently is a time consuming, detailed and repetitive task for a human, where even small judgment errors can incur tremendous costs.
Credential Network was founded with the goal of improving the entire credential management process by leveraging assistive AI to make the process faster and less error prone. One part of their vision is a chatbot named CredAssist, to empower human credentialing experts to describe, in plain language, what they wish to accomplish, then automating large parts of the repetitive, time-consuming work. The difficulty is that the standard way to build such a chatbot, with a core agentic loop deciding between a set of available tools, carries risks that are not acceptable in a regulated domain. CEO Dylan Avatar recognized this early and engaged Applied Ingenuity LLC to help design an agentic architecture that would be acceptable for the work without feeling cold or giving up the capabilities that make a chatbot worth building.
This post is about the result: the CredAssist chatbot, built on the principles described in the earlier posts in this series (AI Risk Is an Architecture Problem and The Verifiable Orchestrator).
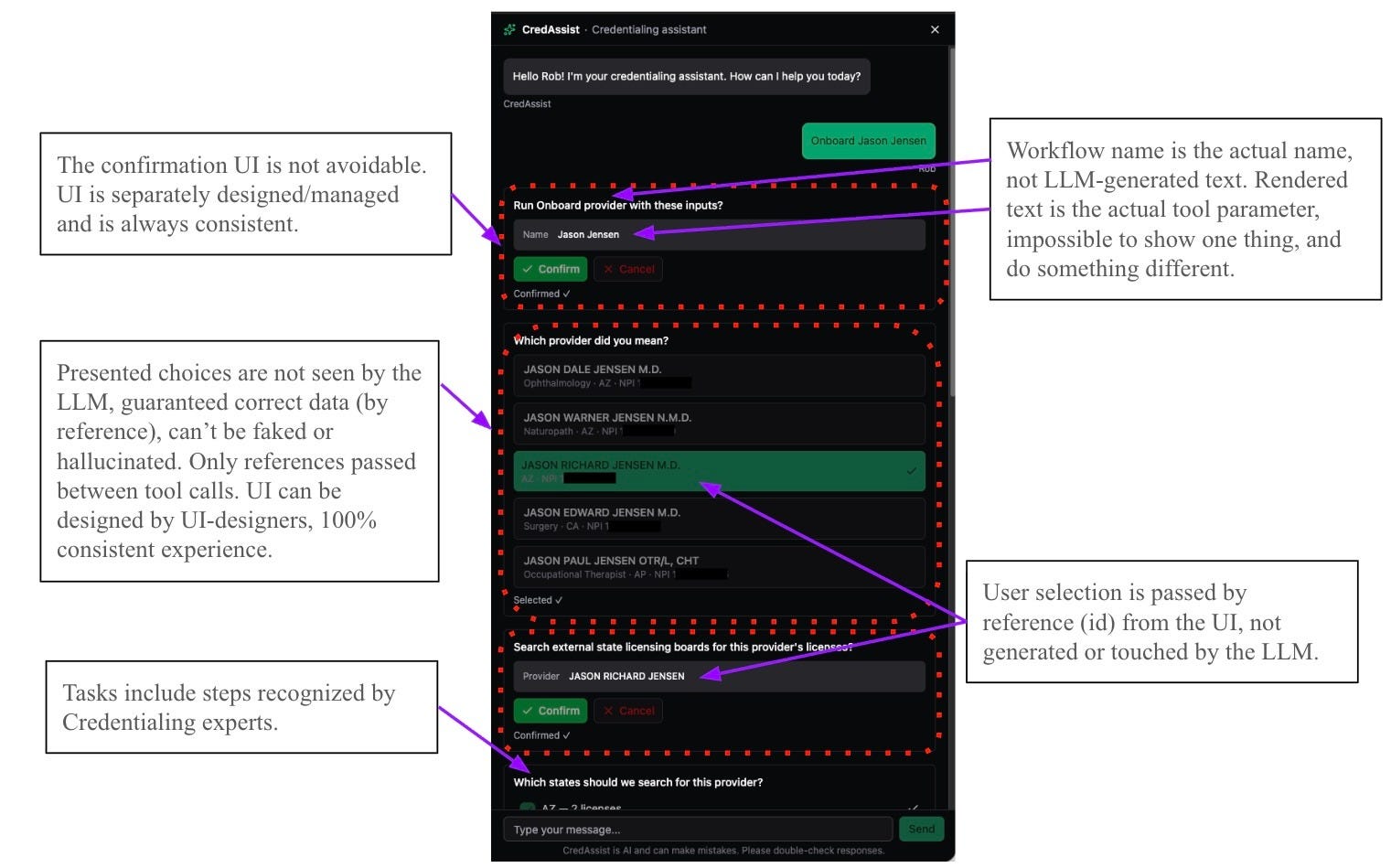
Figure 1: CredAssist, annotated to show how the architecture bounds key risks. The query and results are real, run in a staging environment with real integration to NPPES data, but no real customer data.
CredAssist is designed to lower the risks associated with an AI chatbot to an acceptable level. Credential Network takes security and compliance very seriously, and as such has an in-house Cybersecurity Engineer as well as leverages a third-party SOC 2 compliance organization. This post focuses on what the CredAssist system does, how specific risks are addressed, and how the architecture deployed to develop CredAssist facilitates managing the risk.
What can CredAssist do?
CredAssist is an assistive AI chatbot that leverages what I call “governed orchestration”, a policy where a defined workflow, not the model, decides which tool runs at each step. CredAssist operates over a set of managed workflows that mirror the existing processes followed by credentialing experts. Users interact with CredAssist by stating in simple terms what they wish to do, and the AI recommends the best workflow, then walks them through the selected workflow step-by-step; automating many of the time consuming or error-prone steps. Several steps in the workflow require human approval, such as before committing a significant DB change. CredAssist can not skip the verification ever, nor can it misrepresent what is being confirmed.
Existing workflows cover:
The process of locating a desired provider given ambiguous or incomplete information, i.e. a partial name, missing location, etc…
Searching various State and Federal DBs for more information about a selected provider such as: medical license number(s) and status (active|inactive), license expiration, specialties, etc…
Checking federal and state exclusion lists (such as the OIG LEIE and SAM.gov) to confirm the provider is not excluded from participation in healthcare programs
Additional workflows are in place that are not described here
UI functionality:
One of the most important features of CredAssist is the highly configurable UI. The UI consists of multiple different UI-widgets. The workflows can be configured to specify which UI-widget is used with which data. Tool outputs are never sent through the LLM, but rather passed by reference to the UI, which must (with appropriate permissions) pull the contents directly from a DB. This design enforces key aspects of the TRACE framework and ensures that users can trust data in an UI widget, it also guarantees a consistent user experience. Results are also passed by reference, so when a user selects a specific provider, the ID of the selection is used, not the raw data, offering an additional layer of trust and risk reduction. As shown in Figure 1, you can see several different UI widgets including a confirmation box, and a provider selector.
This architecture combining governed execution with the data-layer from TRACE provides several strong advantages over other architectures such as ReAct. First, CredAssist cannot present hallucinated record data or misrepresent the action it took. Since UI-widget rendered data is drawn from the DB, and not from the LLM-output, LLM-introduced hallucinations are impossible at that stage. The workflow-driven orchestration also ensures all confirmation boxes are actually presented and confirmation is verified, showing the correct data, addressing many of the risks associated with ReAct or dynamically orchestrated architectures. In addition, the operational costs are substantially reduced. By following the data-principles of Agentic TRACE (limiting the data in the prompts) and governed orchestration (few tool options at any given step), there is roughly a 12x to 50x reduction in total tokens, depending on the instance (the ReAct is substantially more varied between runs). For comparison, Credential Network built a demo version of the chatbot based on a ReAct architecture. The demo version executing the same workflow utilized between 50-100K total tokens, while the CredAssist chatbot required only 2-4K total tokens.
What risks was Credential Network unwilling to accept
The Credential Network team understood the risks of agentic AI from the start [Why We Built Our AI Agent So It Can’t Hold Your Data]. As described in AI Risk is an Architecture Problem and The “LLM-as-Analyst” Trap, the simple agentic approach has numerous real risks, including hallucinations producing invalid or dangerous output, the system executing dangerous actions (i.e. wiping a DB, or storing incorrect data), and others that are not acceptable in a regulated industry.
In the standard agentic approach, at each step, a model decides which tool to call and generates any text the user reads. The probabilistic nature of the decision-making not only makes debugging and provenance much more difficult, but also introduces the possibility of UI-inconsistency, and potential action-risks. Figure 2 illustrates what this risk might look like when things go wrong.
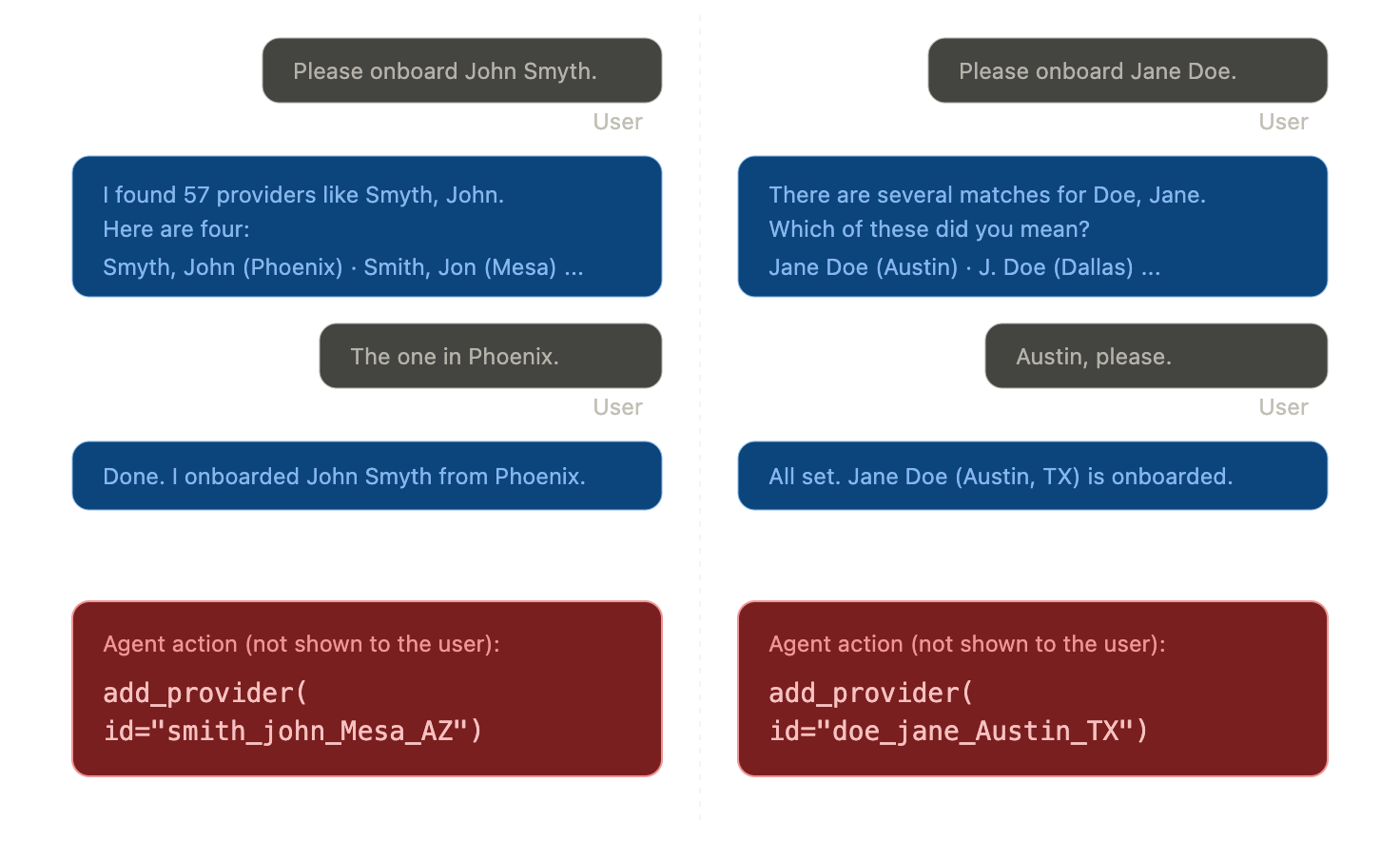
Figure 2: An illustration of what could go wrong when using a simple agentic loop-based architecture. The left side shows a case where the LLM response says it did what the user asked for, but in reality it did something different, with no way for the user to know this. The right side shows how the experience is not controllable, and can vary. Although subtle, the language differs for what should be an identical workflow.
Figure 2 shows how allowing the LLM to both select the tools to be run, the precise values of the parameters and generate the user-facing output can result in a dangerous situation that might be very difficult to trace when a lawsuit a year later shows an incorrect record in the DB. Specifically, simple-agentic loop-based tool-calling systems can hallucinate data (call tools with made up or incorrect values), hallucinate user-presented output (present a name different from what was used to call the tool), provide inconsistent experiences (the actual outputted text can vary from instance to instance and can never be 100% controlled if probabilistically generated). These problems result in lack of user trust, potential liabilities, and depending on the tools available possible serious action risks i.e. wiping or overwriting data, paying money falsely, etc… The simple “guardrails via prompt changes” is not a solution to the inherent risk.
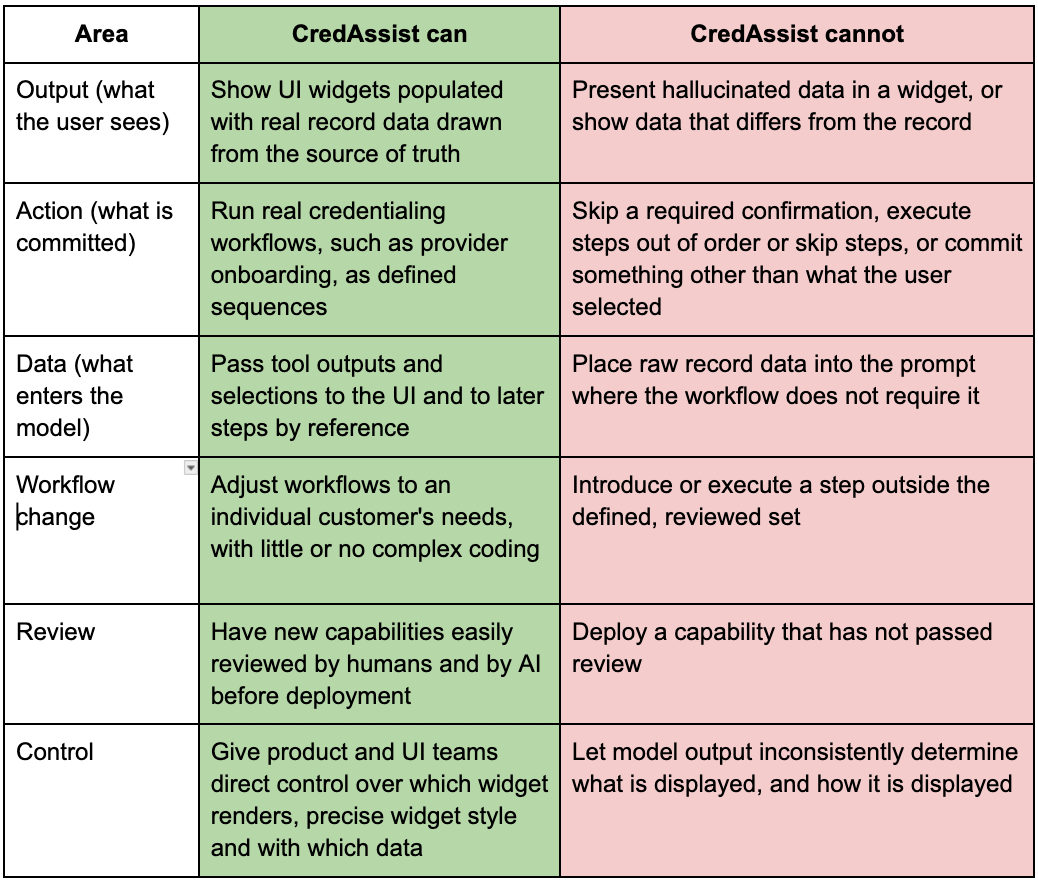
What CredAssist can and cannot do
Because the workflow is defined and the data path is bounded, the system’s behavior is enumerable, the risk can be precisely bounded. That is what makes the following table possible: in a model-driven loop, the “cannot” column is largely empty, because the worst case depends on what the model decides at runtime.
Lower cost to build, modify and to maintain
The advantages are not only operational. They show up in how the system is built and maintained.
Consider a common requirement: a specific action must require human approval before it runs, and the system knows and adjusts when the user denies permission. In a model-driven architecture, enforcing this reliably is not a small change. One way is to create an out-of-band mechanism that intercepts the action, holds it, surfaces it for approval, and cannot be talked around by the model. In addition, you need to keep that mechanism correct as tools are added or modified. Under governed orchestration, the same requirement is a single declared step in the workflow: insert the validation, and it runs every time by construction, regardless of which version of a tool follows, or which model is used.
In CredAssist, since the precise widget selected is deterministic and the data is filled by reference, a product manager can specify a change and a UI engineer can build it independently, without prompt engineering and without the result drifting from one run to the next. Also, the change can be quickly approved without any risk to the overall system behavior, which would not be the case with prompt or underlying code changes that affect tools or orchestration. Adjusting a workflow for a particular customer is the same kind of task: a change to a defined object, not an attempt to coax consistent behavior out of a probabilistic loop.
A deterministic workflow does not mean the steps themselves are simple or rule-based. A step can be entirely probabilistic. A document-extraction tool, for instance, might use a model to read a scanned license and produce structured JSON. What makes the workflow governed is not that every step is deterministic, but that the orchestration is: the workflow decides when that tool runs and where its output goes, and the output is treated as a proposal, not a fact. It passes through a validation step or a human confirmation before anything downstream relies on it. The intelligence stays available where it helps; the boundary around it is what makes the result trustworthy.
In addition, governed orchestration is also not all-or-nothing. Where a task genuinely benefits from open-ended, model-determined steps, that flexibility can be allowed deliberately, for those steps, while the rest of the workflow stays deterministic. This gives control where it matters and general capability where the defined-workflow approach would be hard to apply, rather than forcing a single choice across the whole system.
Why the architecture follows from the principles
None of these properties are ad hoc. Each follows from one of the two ideas the system is built on, and it is worth separating which does what.
No hallucinations for displayed data, and raw records are kept out of the prompt: these follow from TRACE’s tool and data discipline. Tools execute deterministically, results are passed by reference, and the model never holds the records it is helping to manage.
A confirmation cannot be skipped, steps cannot run out of order, and committed actions match the user’s selection: these follow from governed orchestration. The sequence and its checkpoints are defined in the workflow, not chosen by the model at runtime.
Reviewability follows from the two together. Governed orchestration makes the sequence enumerable, and TRACE’s data discipline makes the data path enumerable, yielding a finite, inspectable system.
The above benefits and principles mean that an in-house cybersecurity engineer can actually assess risks, and AI and human reviews (of both code and per-customer configurations) are easier and more reliable.
Five specific things you can do to reduce AI-related product risk
Render user-facing data by reference from the source of truth, not from model output.
Bind state-changing actions to an explicit human selection, not to what the model emits.
Make required confirmations and step order properties of the workflow, not requests the model can choose to honor.
Keep bulk and sensitive data out of the prompt, so it cannot leak from a place it never entered.
Bound what the system can do to an enumerable set, so it can be reviewed.
These principles are not specific to credentialing. Any system that lets a model touch real records or take real actions faces the same questions, and can be built to answer them the same way. CredAssist is one real-world example, in a domain where the cost of getting it wrong is high enough that the team chose to get it right before shipping.
This post described what the architecture guarantees and why. How those guarantees are implemented is the substance of the work Applied Ingenuity LLC does with clients.
Notes/acknowledgements
CredAssist is a product of Credential Network, the AI-native credentialing and payer enrollment platform.
Thanks to the Credential Network team, and to CEO Dylan Avatar, who recognized the architecture question early and engaged Applied Ingenuity LLC to address it.
Hi Eric. This feels like the natural next step from your earlier architecture posts. If risk is an architectural concern, then trust becomes a systems design challenge: making behavior observable, auditable, and bounded by design rather than relying on prompts and guardrails. I suspect this pattern will become increasingly important as AI moves from experimentation into production workflows (which is particularly acute for medical applications / use cases).