
Killing the Hallucination: How to Code Agents That Can Actually Be Trusted, Official Release of the agentic TRACE library
Introducing agentic Trace, The open-source toolkit for the TRACE (Tool-Routed Architecture for Controlled Execution) Framework
agentic_TRACE is Now Open Source — Verifiable AI Data Analysis You Can Run Today
We wrote about why LLM-as-analyst is broken. Then we described the pattern that fixes it. Today we’re releasing the code.
agentic_TRACE on GitHub is an open-source framework for building LLM-powered data analysis agents where the LLM orchestrates but never touches your data. Every number in the output is computed deterministically. Zero data hallucinations. Not “rarely wrong”, it is structurally impossible to fabricate data.
And it runs on the cheapest models available.
The Problem (briefly)
Ask an LLM to analyze your data. Even with perfect database access, it breaks in ways that matter:
The LLM does math in tokens. It retrieves $142.50 and $158.30 from your database, then reports a 12.4% gain in its summary. The real answer is 11.1%. The SQL was correct — the LLM miscalculated when writing the response.
It fabricates when it’s stuck. A query returns no results. Instead of saying so, the LLM produces a plausible-looking table with numbers that came from nowhere.
Stale knowledge poisons results. Ask “compare NVDA’s return to the semiconductor sector average” then the LLM might use its training data to decide which stocks are in the sector, missing recent additions and including delisted companies. Your database knows the truth, but the LLM never checks.
No audit trail. The final output looks identical whether it came from your database, a correct calculation, or a hallucination.
Happy to answer out-of-scope questions. Your company is building a stock tool and someone asks it to write unrelated Python code. Rather than refuse to answer, it happily complies, creating extra LLM costs and brand risk; even prompt-based guardrails can not prevent this all the time.
The deeper issue: traditional agents treat the LLM as the analyst where it retrieves data, computes on it, and presents results, all in the same token-prediction pass. Every step is an opportunity for company embarrassment or silent failure.
We covered this in depth in The LLM-as-Analyst Trap: A Technical Deep-Dive.
TRACE solves this by shifting the LLM from oracle to orchestrator.
How It Works
Three principles:
The LLM sees metadata, not raw data. After every tool call, the LLM receives column names, row counts, and statistics, not raw DataFrames. This makes it structurally impossible for the LLM to fabricate data values; in most cases lowering token counts.
All computation is deterministic. Filtering, aggregation, joins, indicator calculations, and charting are executed by code. The same tool call always produce the same output.
Your data is the source of truth, not the LLM’s training data. When the agent needs to know which stocks are in the “semiconductor” group, it searches your database, not its parametric memory. Your data can change daily. No fine-tuning, no RAG, no prompt stuffing. The LLM discovers what’s available at query time.
Every step is auditable. Each view records its parent views, the tool that created it, and the parameters used. The audit trail is generated by the execution engine, not the LLM.
The agent can only do what you’ve built tools for. There’s no open-ended code execution. If you haven’t registered a tool to delete records or access a table, the agent structurally cannot do it, regardless of what the user asks or how the prompt is crafted.
Full pattern description: The Verifiable Orchestrator: A New Agentic Pattern
See It In Action
Example 1: 18 Semiconductor Stocks, Normalized and Charted
Query:
Plot the semiconductor stocks, normalized to 1, for the last 90 trading days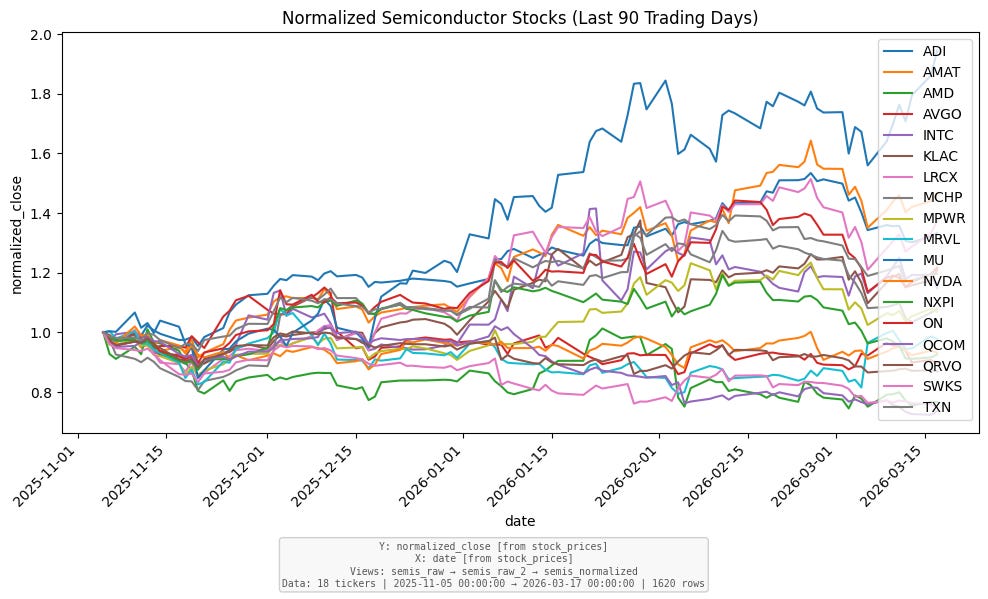
Using the model Gemini Flash 3.1 flash lite: Time: 8.6s Total tokens: 37,307, Prompt (input): 37,004, Output (completion): 303, Max in-context: 7,121 est cost: $0.01
What happens under the hood:
resolve_time— converts “last 90 trading days” to actual market datescreate_view— filters stock prices for 18 semiconductor tickers, specified by the group=”semiconductors” in the date range specified from step 1aggregate— computes normalization baseline (first close per ticker)create_view— adds normalized price columnchart— renders a line chart with provenance annotationpost_finalize— validation confirms output matches the query
The LLM never saw a single price. All 1,620 data points were computed deterministically. And notice step 2: the agent used the database to find which stocks are in the semiconductor group — it didn’t rely on its training data for the tickers. If you add or remove a ticker from that group tomorrow, the next query automatically reflects the change. No retraining, no prompt updates. In addition, this got perfect results in seconds including a chart and a CSV file using a cheap model without requiring advanced reasoning.
Example 2: Complex Multi-Step Analysis
Query:
For each sector, which stock had the highest single-day trading volume since 2022? Show the company name, date, and volume for the top 5 sectors.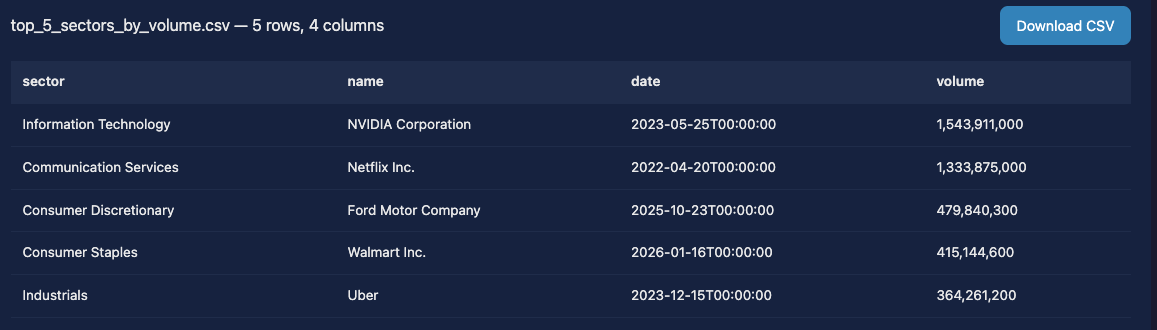
For each sector, which stock had the highest single-day trading volume since 2022? Show the company name, date, and volume for the top 5 sectors.”Figure 3: The data for the query: “For each sector, which stock had the highest single-day trading volume since 2022? Show the company name, date, and volume for the top 5 sectors.”
This query touches more than 500 stocks across more than 3 years of daily data, starting with 56,492 rows. The agent joins tables, aggregates within groups, ranks, and returns verified results. Total time ~10 seconds including ~3 seconds for validation. Total cost: about a penny.
Interestingly, despite having the correct data answer, the LLM-text completely made up the text response incorrectly suggesting that Apple was the highest volume in the time window.
The Small Model Advantage
Every example on this page was run on Google Gemini 3.1 Flash Lite, one of the cheapest commercial models available. The system has run well on local fully open source models.
Why does this work? Because the LLM only makes decisions: which tool to call, with what parameters. All computation is deterministic code. When the LLM makes a mistake such as a wrong column name, missing parameter, or bad syntax, the framework returns a clear error message and the LLM self-corrects on the next try.
The result: a model costing less than a penny per query produces the same verified output as one costing 100x more. It might take an extra iteration to recover from a misstep, but the final data is always correct.
Traditional agentic approaches require expensive models because the LLM is the computation. In TRACE, the LLM is just the planner — and cheap planners work fine when the tools are reliable.
Example 3: When the Agent Doesn’t Know, It Asks
Query:
Show me the computers group stocks for the past month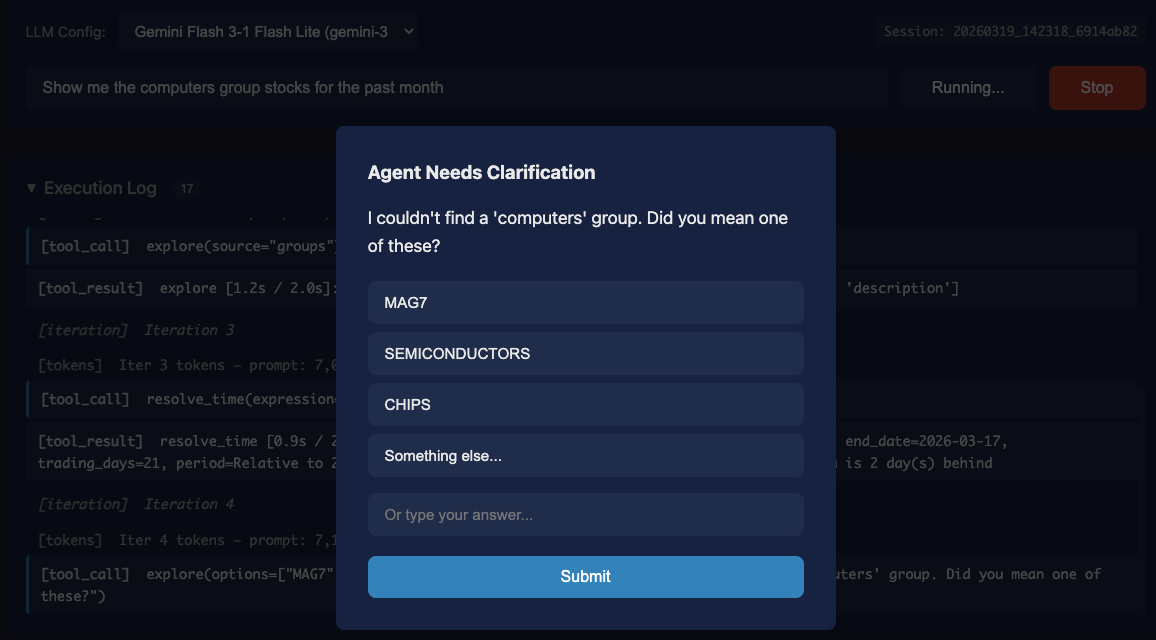
Figure 4: When asked for the “computers group”, the system found there is no exact match and then identified several possibly intended groups, asking the human for clarification. Asking a human is just another exploration tool and is a natural part of this framework.
what happened:
Agent searches for “computers” — no matches found
Agent explores all available groups
Agent resolves time last_month
Agent asks a human which groups the user might have intended since there was no group ‘computers’ and suggests a few it found from step 2. Human selects “SEMICONDUCTORS”.
Agent creates a view that includes all-tickers (only a date filter) and is given a warning that it might have intended to apply a group or ticker filter
Agent creates a new view with the proper group=“SEMICONDUCTORS” and the date filter, covering the current set of semiconductor stocks, regardless of the knowledge of the model.
Agent returns the raw data for the past month as a .csv file, without ever seeing the raw data
The agent didn’t make up “computers group” stocks, but rather asked for clarification using the officially named groups in the database. Then it made a mistake by forgetting to filter the stocks, and immediately corrected by re-generating a view. Despite the hundreds of rows and the missteps, it still took less than 60K prompt tokens total.
Quick Start
Get a free Google Gemini API key, then:
# Recommended you do this in a virtual env
git clone https://github.com/AppliedIngenuity-ai/agentic_TRACE.git
cd agentic_TRACE
pip install -e .
# Load the stock market example
python -m examples.stocks.load_data
python examples/stocks/scripts/data_loader.py --db examples/stocks/data/market.duckdb
# Configure Gemini
export GEMINI_API_KEY="your-key-here"
cp examples/stocks/configs/gemini_3_1_flash_lite.example.yaml \
examples/stocks/configs/gemini_3_1_flash_lite.yaml
# Launch the web UI
python -m examples.stocks.web_app --port 8000
# Connect to the server: http://localhost:8080The stock example covers the S&P 500 (535+ tickers), 40 named groups (FANG, MAG7, SEMICONDUCTORS, HOMEBUILDERS, ...), and 37 pre-built technical indicators (RSI, MACD, EMA, Bollinger Bands, ...).
But the core is domain-agnostic. Swap in your own database and tools, and you have a verifiable agent for your own data domain.
Build Your Own
TRACE is a framework, not just an app. Subclass the tools, register your data sources, write a domain-specific prompt, and you have a verifiable agent for any data domain such as financial, scientific, operational, whatever you need. Your proprietary data stays local, the LLM never needs to be fine-tuned on it, and the agent discovers your schema and terminology at runtime. The stocks example is a complete working template.
What’s Next
This is v1. We’re actively developing and would love your input. Star the repo, file issues, or contribute directly:
github.com/AppliedIngenuity-ai/agentic_TRACE
Read the series:
The LLM-as-Analyst Trap: A Technical Deep-Dive — the problem
The Verifiable Orchestrator: A New Agentic Pattern — the pattern
This post — the code
Built by Eric Glover / Applied Ingenuity
This appears to be a potentially strong pattern shift here: moves the LLM from “doing the work” to “deciding the work.” If I'm reading that correctly, is this where these systems become reliable at scale? So we could count on fewer hallucinations but also auditability + cost efficiency + model commoditization all at once?
Now I'm wondering does this become the default architecture for any data-critical product, or does it introduce enough latency/complexity that teams cut corners back to probabilistic shortcuts?