
Controlled Randomness in LLMs/ChatGPT with Zero Temperature: A Game Changer for Prompt Engineering
Introducing an Innovative Approach to Getting Result Variability With Temperature Set to 0.
Introduction
If you have ever written a prompt for ChatGPT where the output will be machine parsed, you know that the common recommendation is to set temperature to 0 to maximize consistency or rule following. For example, it is recommended to set the temperature to 0 to maximize the chances of producing valid JSON and reduce the need for filtering the output. Unfortunately, for many applications such as for generation of large lists of things from a static prompt - i.e. training data - lack of variability that comes from temperature=0.0 can be problematic.
This post demonstrates a creative and novel way to attain variation of output for a static base prompt, while keeping the temperature at 0. In addition, we will explore why this method works and provide some intuition on what varying the temperature does in the context of how LLMs work. My previous post provides a high-level overview of how LLMs such as ChatGPT work.

The Basic Approach To Achieve Randomness At Zero Temperature
Our basic approach is to leverage the examples as part of a multi-shot prompt (difference between 0,1 and multi-shot prompts and when to use them) as a means of creating “controlled randomness” - without changing the directions part of the prompt. When building a static prompt for a complex task, there are usually several parts.
The base of the prompt - i.e. the directions
Multiple examples (multi-shot) of the desired behavior to increase the likelihood the system will do what you want
Normally, the base and examples are kept constant, the examples are a static part of the prompt.
Our approach changes the static prompt to make the examples dynamic, and determined as a random choice (non-replacement, random order) from a larger set of examples.
With temperature at 0, varying the set of examples (and their order) does not affect the “directions” part of the prompt, but does result in different outputs which are still highly consistent with the examples and objectives of the task.
Understanding Temperature And Result Variability
As described my earlier post, Demystifying LLMS, about how LLMs work as well as many others, most text-generative AI LLMs, such as ChatGPT, Bard, Dolly 2, etc… are all autoregressive systems where the output is generated one token at a time, and the result is fed-back to calculate the scores (probabilities) for the next token.
The probabilities are determined as part of a large deep neural network (transformer) that utilizes multi-head attention to determine how to “understand” the input (prompt + output so far) with regards to selecting the next token.
When performing a completion task (basically generate what is next for a prompt), often many “words” (tokens) are reasonable possibilities. I.e. “The house was X” there are many reasonable values for “X”, including most colors (red, white, blue, …), as well as many other parts of speech (a, built, flooded, sold, glistening). For any given precise sequence of previous tokens, each possible next token has some probability. Always picking the highest probability token would mean always showing the same thing.
The idea of the temperature parameter is that you can add some level of randomness to make the results more varied.


The above two completions were both generated from OpenAi’s text-davinci-003 with temperature 0. Even a seemingly insignificant change in the prompt can change the probabilities of the next tokens. In this case, probably (you can actually check using code from my last post) “city” and “town” are very close in probability, but city is higher when the word “gigantic” is in the prompt and “town” is higher with “giant” - two words which are almost identical to a human.
With the temperature set to the default of 0.7:



The above shows that there are several other possible next tokens which are “close” and with some randomness added via the temperature parameter, they are able to be selected.
What is the Problem - Seems Good to Me…
While the above examples make it look like there is no problem setting temperature to 0.7 as they all make sense and seem reasonable, many experts recommend setting the temperature to 0 for tasks where you care about the precise output, and even small variations can cause a disaster. This is especially true when a secondary process will be parsing the output and expects a precise structure.
For example, if the probability of single quote was slightly less than double quote for a JSON document, randomness could make the difference between valid and invalid. Likewise, if you have a programatic prompt with some header say: “ANS:”, what if “ans:” or “ans-” were slightly lower - picking one of those would mean the results are no longer automatically parsable.
The Use of Examples and Multi-Shot Prompting
Many articles (including my own first post: Tackling Debugging and Developing Effective Prompts for API-products based on ChatGPT) recommend using examples to help the system “do what you want”. The idea is with any prompt, you can use examples “show the system what you want” to help encourage it to “do what you want” - basically you are increasing the probability of selecting the desired tokens. For example, if a prompt says to precede each list item with a number followed by a colon, and I want to be sure it will put a colon and not a period and use the digit for the number instead of the word-name (i.e. “one”), I can have a few examples that start with “1:”, “2:”, “3:”. Given examples, when when it is generate a new entry, “1” is much more likely than “one” and “:” is much more likely than “-” or “.”.
Below are some very simple examples of using examples as part of a completion task.


In both of the above, the completion request was asking it to decide what follows: “The gigantic house was”. By giving examples, you can strongly affect the probabilities of what is next.
Examples can be thought of as how you “clarify what you want”. In the above examples the “prompt” was extremely simple, but in much more complex prompts with many different directives, examples help to constrain what you want the system to do.
The Proposed Approach - Randomize Examples
The proposed approach to achieve “constrained randomness” when temperature is 0 is to vary the examples. An original prompt_template is split into a “header” and “examples” and the examples are randomly selected.
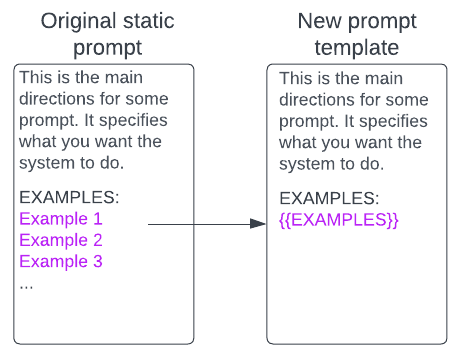
To see the effect of selecting different, but similar, examples, below are two completions.


The above examples show variation in the output for the same main task with a temperature of 0 caused by using different, but similar examples. The proposed approach randomizes the selection (and order) of examples to create variety, without using temperature-based global randomness, that could potentially cause selection of non-optimal tokens.
To illustrate the problem of temperature not set to 0. The same input above, but temperature as 0.9 (extreme):

In the above example, “built to withstand a hurricane” is very different from the pattern of “built on X” or “built in X” from the three examples.
Using Examples To Vary The Output - An Experiment (and code)
To illustrate the way we can use examples to vary the output - even with temperature of 0, lets create an experiment. The goal is to create a static “primary prompt” to generate several band names, but with a few constraints/rules. We want to quantify the effects of temperature and random variation of examples.
Metric Categories
Variability - i.e. how much variation of output is there from repeated runs with the same "base prompt”
Rule following - i.e. does the output produce something that violates stated requirements
Consistency with examples
Lets do this!
Set-up:
import os
from dotenv import load_dotenv
import openai
import re
import random
from collections import defaultdict
# Lets load the OpenAI key:
load_dotenv()
ENV_DATA = os.environ
# Lets send the prompt to OpenAI's API
DEFAULT_MODEL = "text-davinci-003"
def get_response(prompt, temperature=0.0, max_tokens=1000, debug=False, model=DEFAULT_MODEL):
openai.api_key = ENV_DATA["OPENAI_API_KEY"]
response = openai.Completion.create(
model=model,
prompt=prompt,
temperature=temperature,
max_tokens=max_tokens,
frequency_penalty=0,
presence_penalty=0
)
res = response["choices"][0]["text"]
if debug:
print(response['usage'])
return resLets create an initial prompt:
prompt1 = """
You are an AI. Your job is to generate interesting band names.
Generate 5 interesting band names, related to the topic of math.
Each of the band names should start with BAND: and be on a separate line with no numbers.
Example band names:
BAND: Binary Expressions
BAND: Algebraic Linear Transformations
BAND: Trigonometric Functionality
BAND: Prime Time Factorization
BAND: Calculus Congruence Conjecture
OUTPUT:"""For the above prompt:
We ask for exactly five results per iteration
We require it be “related to the topic of math”
We require each result starts with “BAND:” and is on a separate line
The examples clarify when we say: “related to the topic of math” we mean every word must be math-related - yes I know this makes for dumb band names, but that is not the point of this experiment.
We run ten times for each of three temperatures: [0, 0.35, 0.7] - noting that 0 is strongly recommended for cases where “following the rules matters” and for the OpenAI Playground, 0.7 is the default.
# Lets run 10 times for each temperature and analyze!
original_results=defaultdict(list) # key is temperature
for temperature in (0.0, 0.35, 0.70):
print("Running for temperature: {}".format(temperature))
for i in range(0,10):
print(i)
res = get_response(prompt1, temperature=temperature)
original_results[temperature].append(res)What does the output look like?
For temperature = 0:
BAND: Geometric Progression
BAND: Logarithmic Oscillations
BAND: Quadratic Equations
BAND: Polynomial Solutions
BAND: Statistical VariablesFor temperature = 0.7 (here are two sets of the 10 iterations)
BAND: Mathematical Melodies
BAND: Equation Ensemble
BAND: Geometric Grooves
BAND: Prime Polyrhythms
BAND: Numerical Noise Makers
-----------------------------
BAND: Logarithmic Labyrinth
BAND: Geometric Groove
BAND: Arithmetic Angles
BAND: Pythagorean Pulses
BAND: Statistical SynchronyLets automatically analyze
We can check for:
There are exactly 5 bands
Each band starts with “BAND:” (and is on a newline)
Result variation - there are many potential metrics, for simplicity, lets just count total unique words across all 10 runs (we can adjust if too many or few results as needed)
def analyze_results(results, temperature, target_number_bands=5):
# we want to first see how many times they "followed the rules"
# - exactly 5 band names, all starting with BAND:, separated by newlines
num_with_five_bands = 0
# Variation: total unique words are present across all runs
seen_words = set()
for res in results[temperature]:
# lets split on the \n, skip the first (always starts with "\n")
bands = re.split("\n", res)[1:] # the first is blank!
# lets check that they all start with BAND:
num_bands = len([x for x in bands if x.startswith("BAND:")])
if num_bands == target_number_bands:
num_with_five_bands += 1
all_words = set(re.split("\s+", res))
seen_words |= all_words
seen_words.discard("")
seen_words.discard("BAND:")
return num_with_five_bands, len(seen_words)The above code produced the following results from our run

From the above results, you can see that for all three temperatures, there were exactly 5 syntactically valid results. Also for temp=0 since every result had two word band names, all ten runs produced identical outputs (all words were different in a single iteration). As expected, temperature=0.7 had much more variation between iterations (in total number of unique words) than a temperature of 0 or 0.35.
An important note - at first I tried a much more complicated prompt involving additional restrictions such as each band had to have exactly three words. With that prompt, no temperature, even 0, could follow it “reliably”, so I decided to simplify it a little bit.
It is interesting to note though, that with the prompt I chose every iteration “followed the rules”. What about the variations? As you can see from the small set of examples pasted above, the higher the temperature, the “less closely” it followed the examples by using only math terms. Specifically, randomness (temperature), seemed to include some music-related terms. This could be because “music” is close to both “band” and “math”, terms in the prompt, the probabilities were higher than other terms. The system has a default assigned penalty for repeating terms, otherwise the system might have selected the same term for every word in the output.
I manually went through each of the 150 results and counted how many band names contained “music” terms which are not valid math terms - this is highly subjective, some words, such as “frequency” and “chord” are arguably both math and music, and I generally didn’t count those as “music” terms.
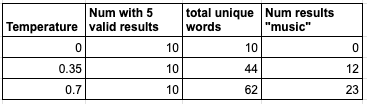
From the above chart (adding “num results music”) - you can see that as temperature went up, the “following the theme of the examples” weakened and the amount of “music” went up. While in this case, using music-terms arguably makes more interesting band names, the examples in the prompt clearly set the scope as only math words. In other problems, the variation could be much worse, even violating a strict rule. As shown above, current LLM-transformers in general are extremely sensitive to minor changes in the prompt.
Adding randomness to temperature = 0
Lets change our prompt to be a prompt template and set up a few extra multi-shot examples:
prompt_template = """
You are an AI. Your job is to generate interesting band names.
Generate 5 interesting band names, related to the topic of math.
Each of the band names should start with BAND: and be on a separate line with no numbers.
Example band names:
{{EXAMPLES}}
OUTPUT:"""
random_examples = [
"BAND: Binary Expressions",
"BAND: Algebraic Linear Transformations",
"BAND: Trigonometric Functionality",
"BAND: Prime Time Factorization",
"BAND: Calculus Congruence Conjecture",
"BAND: Differential Equations",
"BAND: Cosine Calculus",
"BAND: Radical Quadratic Ratios",
"BAND: Geometric Sequences",
"BAND: Exponential Curves"
]As described above, we removed the examples from the original prompt and made them {{EXAMPLES}} as part of a prompt template. The first five examples are identical to those used in the original prompt.
Code to generate the randomized-example prompt:
def generate_prompt_with_random_examples(prompt_template, examples, num_examples_to_include=5):
random_examples = random.sample(examples, num_examples_to_include)
prompt = prompt_template.replace("{{EXAMPLES}}", "\n".join(random_examples))
return promptLets run the experiment again - but use a prompt with randomized examples. NOTE: Originally I looped first through temperature, however - to be fair, each different temperature needs to have an identical prompt, so I had to iterate differently: generate one prompt for each iteration, then inner-loop temperature. For this experiment, I only ran with temperature of 0 or 0.7.
randomized_results=defaultdict(list) # key is temperature
for i in range(0,10):
prompt = generate_prompt_with_random_examples(prompt_template, random_examples)
for temperature in (0.0, 0.70):
print("{}: temperature: {}".format(i, temperature))
res = get_response(prompt, temperature=temperature)
randomized_results[temperature].append(res)Lets look at a few actual outputs - this time temperature = 0 varied
TEMPERATURE = 0, random pick 5 examples out of 10
-------------------------------------------------
BAND: Prime Polynomials
BAND: Logarithmic Logic
BAND: Fractional Fervor
BAND: Exponential Expressions
BAND: Integral Intuition
-------
BAND: Logarithmic Loops
BAND: Polynomial Powers
BAND: Trigonometric Triangles
BAND: Prime Proportions
BAND: Fractional Fusions
-------
BAND: Logarithmic Lyricism
BAND: Geometric Grooves
BAND: Polynomial Progression
BAND: Arithmetic Allegiance
BAND: Statistical Symphonies
TEMPERATURE = 0.7, random pick 5 examples out of 10
---------------------------------------------------
BAND: Logarithmic Limitations
BAND: Quadratic Dynamics
BAND: Imaginary Exponents
BAND: Fractal Fractures
BAND: Prime Probabilities
-----
BAND: Theorem Troubadours
BAND: Logarithmic Lyricists
BAND: Algebraic Anthems
BAND: Trigonometric Trio
BAND: Fractional Funksters
-----
BAND: Geometric Geometry
BAND: Numberic Numerators
BAND: Logarithmic Logistics
BAND: Sine Symmetry
BAND: Theorem TheorizingAnalyzed results:

Unfortunately, it is not always obvious which terms are music, but not math - so I did my best…
The key points are:
As before all instances followed the syntax/structure rules
Temperature = 0 showed significant variation of terms across iterations, almost as much as the original prompt with temperature = 0.35
There were some music terms as before, but this time even with a temperature of 0, but as before, the higher temperature had more deviation from the examples.
Why did the temperature = 0 case include music results? While I can’t know for sure, I suspect that some combination of examples pushed it “towards music” more than others1. It is interesting to note that it was different iterations that had music terms between temperature of 0 and 0.7, so if the hypothesis that some combinations of examples drive it toward music, then either there was something different on the backend, or by sheer randomness the temperature of 0.7 selected math instead. Also, it seems like once one music term was selected (as the second word in the 2-word band names), the following band names in the same iteration had their second word as music.
Developing an Intuition for Temperature Randomness vs Exemplar-Based Randomness
One way to think of temperature created variations vs randomized-example-selection caused variations is in the figure below. NOTE: a broad over-simplification/approximation!

When temperature is 0 you get a single point of output - one which maximizes the probability (i.e. the best attempt at “what you want”). As temperature increases, you get small variations “near” the temperature = 0 point. When you vary the examples - potentially using examples from the set of valid outputs - you shift the point on the manifold. When you raise temperature, you draw from “nearby” points - which could include valid ones as well as those which might not be acceptable. The chance that a random temperature-created variation is “good” (i.e. within the gray area) totally depends on the problem as well as the LLM’s model and many factors including how many attention heads, etc... For some problems, like returning JSON - many variations of tokens could render the output invalid, however, for completing a sentence, with few constraints, most variations are probably still “good”.
It is important to note that it is not guaranteed (well mathematically, I can’t prove it) the space is symmetric in that, some combinations of examples which themselves are considered valid, could result in an invalid output even at temperature of 0. Having examples which are ‘bad’ could easily push the outcome to be unacceptable, so be certain the examples used for random selection and inclusion in the prompt are all very good. Despite the set ten of source-examples all seeming “good”, the randomization had one run where “music” appeared even with temperature of 0. Also - I suspect the variation of the examples between random selections might affect the variation of outputs. I.e. if all of the possible examples are very similar, you might not get as much variety of outputs than if they are substantially different.
Conclusion
Varying temperature can cause random-variations “near” the desired output, which in some cases is undesirable. As an alternative to varying temperature, you can achieve randomized result variation by changing the set of included examples in the prompt. This experiment shows (at least in this single case) that as you vary examples, but keep temperature at 0, you introduce variations in the output which are more consistent with the prompt than you would get by changing the temperature.
Remember YMMV, and use my code snippets at your own risk. Remember that the world of generative text-AI is very new and things are changing very fast. What works today might not tomorrow, or they might invent a new architecture where temperature is irrelevant, or setting it greater than 0 will have no effect on the probability of following the rules/producing valid outputs.
If you have read this far, be sure you are a subscriber. As a subscriber (even a free one), you can have access to polls and will get e-mail notifications when I make a new post. Some really exciting posts are coming up!
Quick Poll
When playing with the API, once in a while the system did strange things, without triggering an error. While the temperature of 0 almost always produced identical output for the same prompt, there were occasions where there was a totally different result. It is possible that this is some experiment by OpenAI, a bug, or there are other factors causing inconsistent outputs.